
CMU15445 P3
1. Preview
做P2花了很长时间,P3做起来相对于P2要容易一些,因为测试样例都在本地,所以也不会被奇奇怪怪的bug困扰。
P2与P3的差别还是很明显的,P2是让我们从0实现一个B+树,而P3则更偏向考察阅读代码的能力,感觉整个P3的难点就在阅读代码、理解代码的部分,整个过程中我主要遇到的困难就是知道该怎么写,但是找不到对应的接口在哪,所以阅读代码是完成P3的一个非常重要的部分。
在这个Task里,我们已经可以使用BusTub shell来执行SQL查询了,自己代码的实现可以直观的看到了
同时,也要记得和网页版的bustub比对一下,就像P2的B+ tree Printer一样
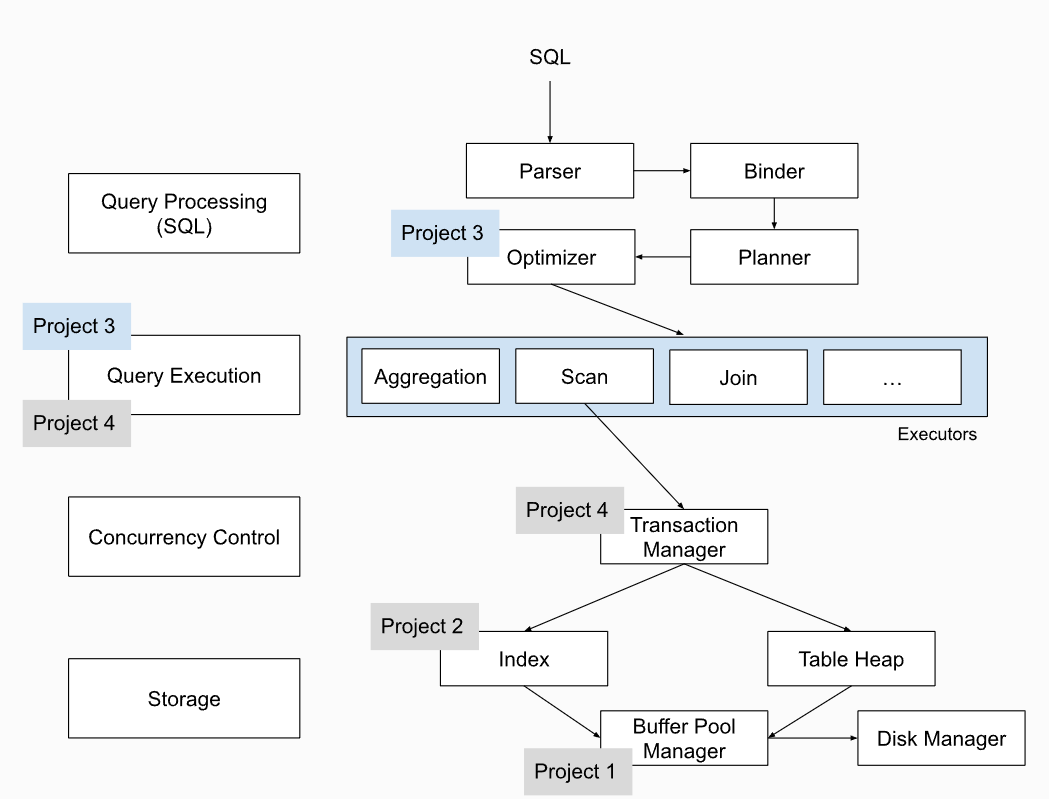
这是P3给我们的整体架构,P3就是实现Optimizer部分。
一个SQL走进来,要经过Parser、Binder、Planner和Optimizer,他们的作用分别是什么呢?
Parser
Parser(解析器):
- 解析器负责将输入的SQL查询字符串解析为语法树或解析树。这个树状结构表示了查询的语法结构,包括查询的关键字、表名、列名、操作符、条件等等。
- 解析器会验证查询是否符合SQL语法规则,如果查询包含语法错误,解析器将抛出错误信息。
- 解析器通常将查询转化为一种内部数据结构,以便后续的处理器(如查询优化器和执行引擎)能够更容易地处理和分析查询。
一般情况下会使用第三方库
Binder
Binder(绑定器):
- Binder是SQL查询处理的下一步,它负责解析器生成的语法树中的语义分析和绑定过程。
- 绑定器的主要任务是将查询中的各个元素与数据库中的实际对象进行关联,例如将表名和列名映射到实际的数据库表和列。
- 绑定器还会执行权限检查,以确保用户有权执行查询中指定的操作。
- 在绑定阶段,还会对查询中的一些元素进行类型检查,以确保操作符和操作数之间的数据类型兼容。
到这里,便生成了一棵Bustub可以理解的抽象语法树(AST)了。
Planner
Planner(计划生成器):
- Planner是数据库查询处理的一部分,它的主要任务是将解析器生成的查询语法树转换成可执行的查询计划(Execution Plan)。
- 查询计划是一种数据结构,描述了如何执行查询,包括了查询的执行顺序、使用哪些索引、连接哪些表、应用哪些过滤条件等等。
- Planner需要考虑查询的复杂性、数据量、索引情况等因素,以选择一个高效的执行计划。
- 这个执行计划将被传递给优化器,后者将进一步优化它以提高查询性能。
这一步,遍历AST,生成查询计划,查询计划同样是一棵树的形式
Optimizer
Optimizer(查询优化器):
- 优化器是数据库查询处理的重要组成部分,它的任务是接收查询计划并尝试找到最佳的执行路径,以最小化查询的执行时间和资源消耗。
- 优化器会考虑多个执行策略,例如不同的连接顺序、索引使用、表扫描方式等,然后评估这些策略的成本,并选择最佳策略。
- 为了评估执行策略的成本,优化器需要统计信息,例如表的大小、索引的选择性、磁盘I/O成本等。
- 优化器的目标是生成一个执行计划,使查询在给定的资源约束下尽可能高效地执行。
最后,再有优化器优化查询计划。
考虑一个复杂的SQL情况
1 | bustub> EXPLAIN SELECT colA, MAX(colB) FROM |
Planner给出的计划是:
1 | === PLANNER === |
可以看到,本来很复杂的planner被优化成了
总的来说,Parser和Binder是SQL查询处理的前两个关键步骤,它们负责将用户输入的SQL查询字符串解析为可执行的语法树,并将查询中的各个元素与数据库中的实际对象进行关联和验证。完成这些步骤后,查询就准备好由查询优化器进一步优化,并由执行引擎执行。Planner负责将查询语法树转化为查询计划的初始版本,而Optimizer负责进一步优化这个计划,以确保查询在数据库中以最佳方式执行。这个优化过程对于提高查询性能和减少资源消耗非常重要,尤其是在处理复杂查询时。
接下来就是执行算子了,也来到了我们project要实现的部分
2. Task1
获得了最终的查询计划后,轮到执行算子出场了。
这里使用的是火山模型,每个算子有Init()和Next()两个函数,分别对应了算子的初始化和向上层吐数据的部分。每一次调用Next()都会向上层算子吐一组tuple,有效避免了内存占用的问题
Task1需要我们实现SeqScan、Insert、Delete和IndexScan四个算子,其中SeqScan和IndexScan类似,Insert和Delete类似,可以分成两组进行分析
2.1 Scan
Seqscan
先从Seqscan开始说,Scan就是遍历整个table,没什么难度,利用Bustub给我们的Table Iterator可以轻松实现,这里主要看一下Bustub的数据结构
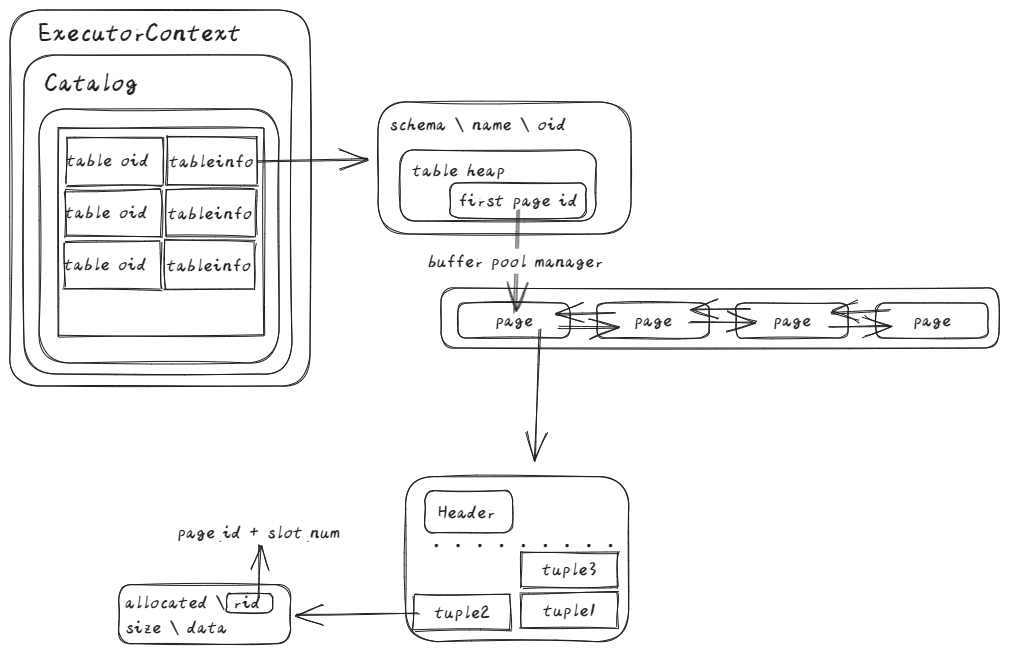
可以看到table info存在Catalog里,并且由table Heap保存整个表的first page id, 经由此才能拿到tuple
获取table info后,将table iterator置为table heap的**begin()**,之后每次调用Next()函数,++iterator即可
IndexScan
IndexScan也是类似的,和SeqScan的区别就在一个拿到的是table info,一个是index info
多提一下,这里的index就对应着P2中我们实现的B+ tree,用Index iterator的时候,用到的接口都是我们在P2中实现的,!=、解引用*、++等重载函数也是我们亲自实现的。整个创建索引的过程,我们已经深刻理解(备受折磨)了。
2.2 Write
Insert和Delete是为二的写算子了,在写的同时不仅要将值在表中写入/删除,同时如果这个表有索引,还需要在其对应的索引中执行操作。最后要输出修改的元组数量。
不断调用子算子的Next()函数获取要进行操作的元组,然后遍历表的所有索引组,依次将新的tuple及其索引插入索引即可,同时不要忘记记录修改的tuple数量
tips:有一些会用到的接口函数比如InsertTuple()、InsertEntry()等等需要自己多看几遍代码,多读多记会有很大的帮助的,找不到也别着急,慢慢来(反正我急死了)
3. Task2
Task2要实现的算子相较Task1要复杂一些
3.1 Agg
聚合算子在实现的时候会有一个简化设计的假设,即聚合哈希表可以全部存入内存,不需要实现聚合的两阶段(分区、重哈希)。
除此之外,还要注意区分*count()和count(column)的区别,count(*)包含所有的列,相当于行数,统计结果的时候不会忽略NULL值,而count(column)**则会忽略NULL值
聚合类型只有以下五种,没有要求实现avg
1 | enum class AggregationType { CountStarAggregate, CountAggregate, SumAggregate, MinAggregate, MaxAggregate }; |
通过头文件可以看到插入agghashtable需要agg_key和agg_value,这里的KV需要通过MakeAggregateKey()函数和MakeAggregateValue()函数将tuple转化为对应的agg_key和agg_value。这里的key是分组字段的排列组合,比如下面这条SQL:
1 | SELECT count(*) FROM t1 GROUP BY gender, grade; |
这里的key就是<gender, grade>的排列组合,比如性别分为man和woman,grade有ABCD四个等级,那么最后的key就有8组分别为<man, A> \ < man, B> \ <man, C> \ <man, D> \ <woman, A> \ <woman, B> \ <woman, C> \ <woman, D>
value就是agg对应的列值,比如**sum()**就是将每次的值累加
所以总的来说就是先分组,再聚集
头文件里给的aht_就是我们要在Init()函数中做的聚集哈希表初始化,先将表内信息按照key分好组别,再对各组的value进行聚集。
Init()函数里,将子算子吐出的tuple插入聚集哈希表中,再在Next()函数中完成聚集的操作。如果是个空表,那么count()返回0,其他聚集操作返回*NULL
3.2 NLJ
P3中只要实现NestedLoopJoin, 对HashJoin没有做要求(后面优化的时候还是要做一下),NestLoopJoin的逻辑非常简单,就是遍历两个表,如果配对成功就将其组合成的新tuple输出即可
1 | for outer_tuple in outer_table: |
要注意的是,为了使left_tuple和每个right_tuple进行比较,需要预先将right_tuple存至一个新的数组中,每次从左孩子中拉取一个tuple,与新数组进行比对,比对成功则组合并输出。这里有个很关键的问题,left_tuple与right_tuple的匹配可能存在多个,如果匹配成功后直接开始下一个left_tuple的match环节,那就会遗漏,所以可以设置一个cur,记录新数组中的index,如果没有到最后一个,那么left_tuple不用改变,继续与后面的right_tuple进行比对,直到遍历完新数组,再获取下一个left_tuple, 这样就不会有错过的匹配项了
3.3 NestedIndexJoin
同样是Join操作,当存在相等条件且恰好该条件在右侧表中存在索引,DBMS将会使用NestedIndexJoinPlanNode
具体操作于NLJ类似,区别在匹配时通过Key_predicate构造出probe key, 这里P3帮我们简化了一些要考虑的情况,不会存在重复行及奇怪的情况(P2也是这样,没有重复key),所以如果有错误,对着测试用例改改即可
!!不要忘记区分left_join和inner_join
4. Task3
task3需要我们实现Sort、Limit算子和Top-N优化
4.1 Sort
在没有index_key的情况下,order_by会采用SortPlanNode进行排序
这里主要使用std::sort的标准库函数,自定义排序可以实用lambda表达式,对order_bys中获取的关键字进行比较,compare函数已经给好我们了(CompareLessThan和CompareGreaterThan),我们只需要区分升降序即可,默认或者ASC即为升序,DESC则是降序,清楚之间的关系再进行实现就比较容易了
关键内容如下:
1 | std::sort(sorted_tuples.begin(), sorted_tuples.end(), [](const Tuple &a, const Tuple &b){ |
4.2 Limit
Limit限制查询生成的tuple数量,比Seqscan多一个count记录输出tuple数量,一旦达到限制数量即停止
4.3 Top-N optimizer
到了最后一个任务,我们需要修改optimizer使Limit+sort的组合通过Top-N执行算子执行。
默认的情况先将所有的tuple排序(sort excutor), 然后再取排序的结果前N个最小元素(limit excutor),TopNExcutor要做的是在排序的过程中收集N个最小的元素,动态更新。
这里与之前的任务有些不同,之前的任务仅需要修改对应的执行算子,这里还需要修改src/optimizer/目录下的optimizer_custom_rules.cpp目录中的各个优化函数,这里主要是OptimizerSortLimitAsTopN()
一上来无从下手可以先阅读其他优化规则,比如OptimizerNLJAsIndexJoin()
1 | std::vector<AbstractPlanNodeRef> children; |
对plan进行后序遍历,如果执行算子满足特定条件则进行优化,比如这里的NLJAsIndexJoin
1 | if (optimizerd_plan->GetType() == PlanType::NestedLoopJoin){ |
与NLJAsIndexJoin相比SortLimitAsTopN的逻辑就简单很多
1 | if (optimizerd_plan->GetType() == PlanType::Limit) { |
自底向上遍历各个算子,如果该算子执行Limit操作,且其下层执行Sort操作,则可以将两个节点替换为TopN算子
实现可以使用优先队列(std::priority_queue),主要是要设计好自定义比较器,之前一直用的默认比较类型,这里学习了一下对自定义类的比较器做法
1 | std::priority_queue<Tuple, std::vector<Tuple>, decltype(cmp)> pq(cmp); //cmp 为自定义比较函数 |
至此,P3所有的必做项目都已完成
Leaderboard
Leaderboard部分我没有很仔细的去做,网上也看到了很多大佬提供的各种方案,打算等有时间再进行仔细研究、尝试,这里我只实现了HashJoin,对Query1有一定的优化,Q2和Q3的优化就放到以后了-。-
HashJoin主要对Join操作进行的优化,在optimizer_custom_rules.cpp中将注释的那行取消注释即为开启NLJAsHash优化,进去看一下可以看到,该优化器会将类型为NestLoopJoin且比较类型为Equal的操作,优化为HashJoin,我们实现HashJoin Excutor即可
HashJoin主要分为两个阶段:
- Build阶段
将右表数据存入哈希表
- Probe阶段
扫描左表,在哈希表中查找,存在对应值则匹配
在Init()阶段遍历右表,其tuple调用HashValue()后存入哈希表,再遍历左表,将其与哈希表中tuple进行匹配,leadborad测试样例只要求了inner join,但是其他测试样例需要我们区分inner join和left join,在打开NLJAsHash优化策略后,其他的Join操作也会被优化为HashJoin,所以要考虑到left join,和之前的要求相似,这里就不再赘述。最后将匹配上的new tuple放入临时的数组,Init就完成了
Next()函数就如之前一样,不断emit tuple即可。
Debug && Sum Up
这里debug可以用GDB
1 | gdb ./bin/bustub-sqllogictest //gdb |
也可以make shell
直接用IDEA(我用的vscode)在对应执行器中打断点,再输入出错的SQL语句,以定位错误
至此,P3结束,开始P4篇章!


